DeepSeek模型是由中国顶尖AI团队深度求索公司开发的一系列大语言模型(LLM),其核心目标是通过技术创新实现高效、低成本的AI模型训练与推理,同时在多模态任务中展现卓越性能。
DeepSeek模型的详细介绍:
1. 模型架构与技术特点DeepSeek模型基于Transformer架构,采用了混合专家架构(MoE)和多头潜在注意力机制(MLA)等先进技术:
- 混合专家架构(MoE) :每个MoE层包含一个共享专家和多个客户端,通过动态冗余策略在推理和训练过程中保持最佳负载平衡,显著降低计算成本。
- 多头潜在注意力机制(MLA) :通过低秩联合压缩机制将Key-Value矩阵压缩为低维潜在向量,减少内存占用并提升推理效率。
- DualPipe通信加速器:优化GPU集群中的数据传输和处理,减少通信开销,提升训练效率。
- FP8混合精度训练:使用NVIDIA的Tensor Cores加速器,提高训练速度并减少内存使用。
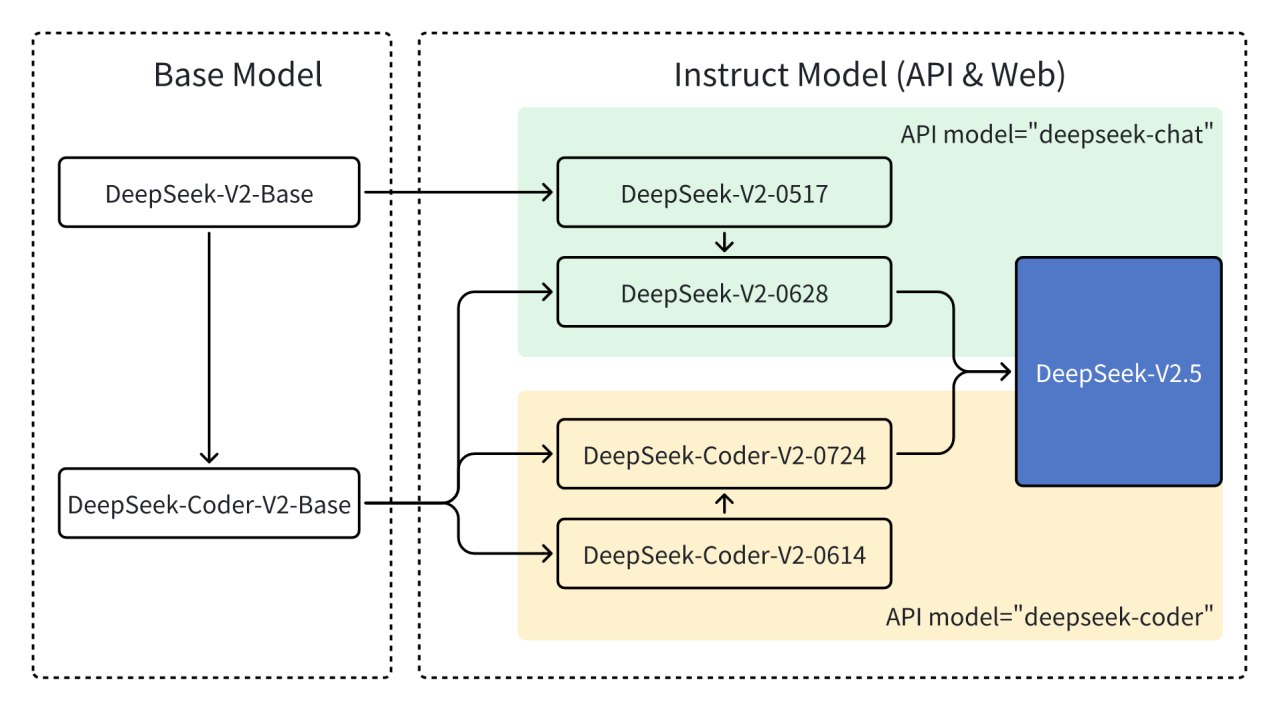
2. 版本与性能DeepSeek系列模型包括多个版本,如DeepSeek-V3、DeepSeek-R1等,各版本在性能、应用场景和技术特点上有所不同:
DeepSeek-V3:
参数量:671亿,激活参数量370亿。
训练成本:仅需280万GPU小时,总成本557.6万美元。
性能:在多项基准测试中超越Qwen2.5-72B、Llama 3-1.40B等开源模型,达到与GPT-4o和Claude-3.5-Sonnet等顶尖闭源模型相当的水平。
应用场景:支持长文本生成、数学推理、代码生成等多领域任务。
DeepSeek-R1:
基于强化学习和监督微调阶段提升推理能力。
性能接近OpenAI的o12模型,但训练成本仅为后者的十分之一。
3. 训练与部署DeepSeek模型的训练和部署具有以下特点:
- 高效训练:通过渐进式分层蒸馏技术,实现“大模型智慧,小模型效率”的目标。
- 低成本部署:运行成本仅为OpenAI的3%左右,显著降低了企业的使用门槛。
- 开源支持:部分版本如DeepSeek-V3的源代码已开源,便于研究社区进一步优化。
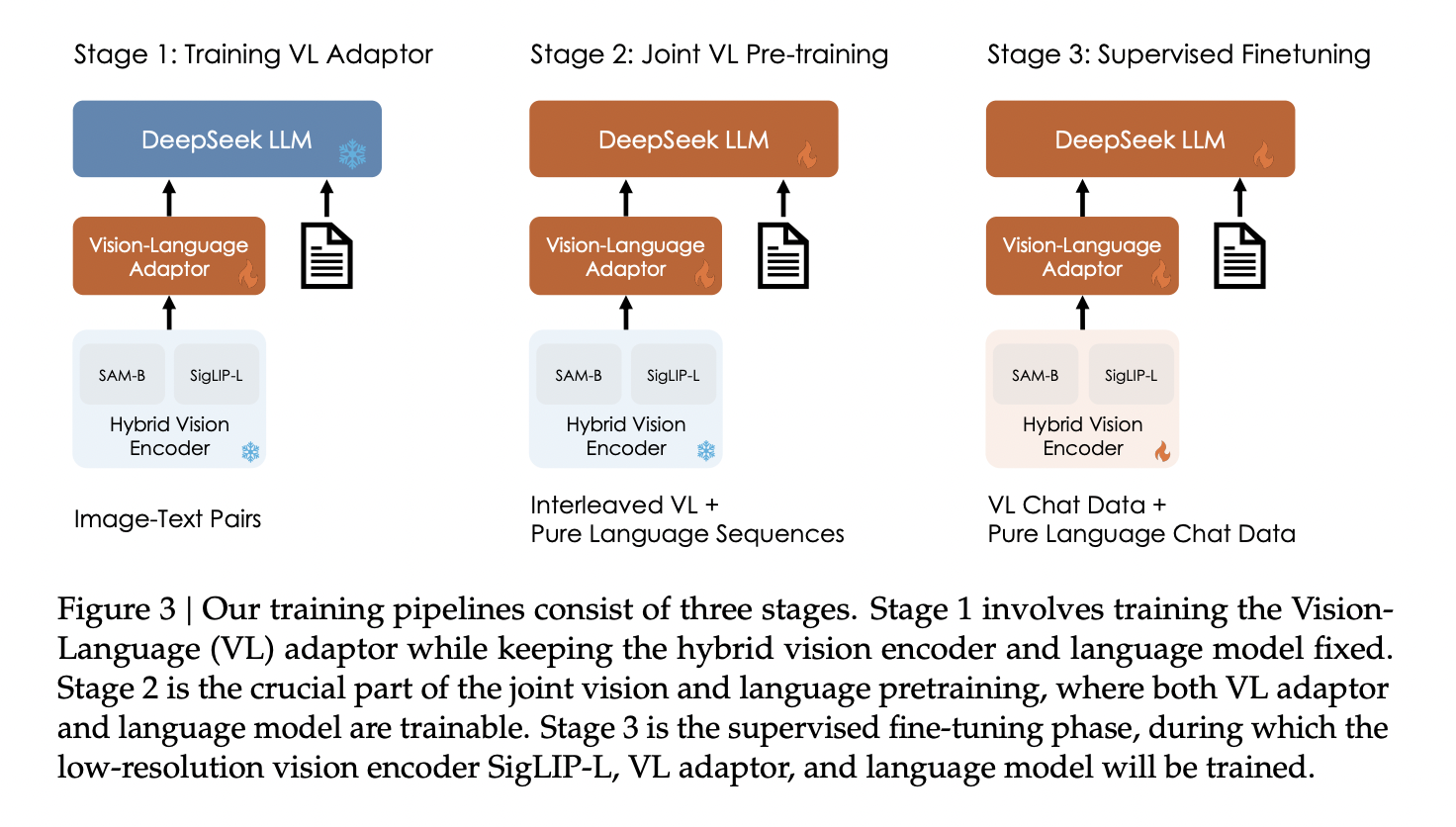
4. 应用场景DeepSeek模型广泛应用于以下领域:
自然语言处理(NLP) :包括文本生成、分类、翻译等。
代码生成与逻辑推理:适用于代码编写、数学推理等复杂任务。
多模态任务:支持文本与代码混合输入,优化多模态交互。
搜索引擎与聊天机器人:提供基于上下文的搜索结果和AI驱动的对话功能。
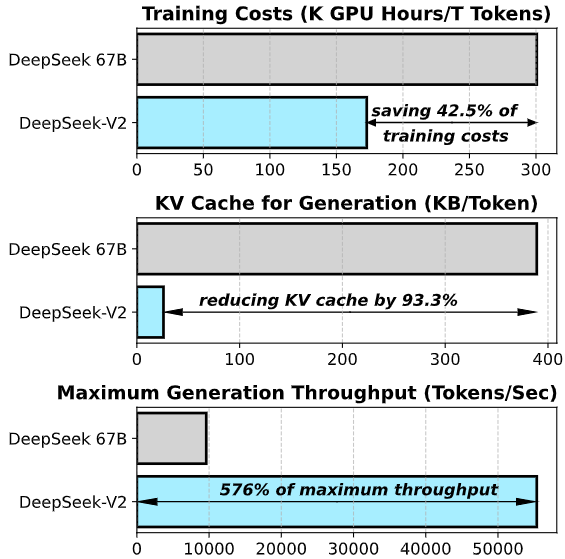
5. 技术优势DeepSeek模型在多个方面展现了显著的技术优势:
高性价比:相比OpenAI的GPT-4,DeepSeek-V3的训练成本低10倍,推理成本低9倍。
多语言支持:支持多种语言和技术领域,能够生成不同语言的问题响应。
推理效率:通过动态路由和负载均衡策略,显著提升推理速度。
6. 未来展望DeepSeek团队计划在未来推出更大规模的模型(如100B参数级别),并探索在科学发现、材料设计等领域的应用。此外,随着技术的进一步发展,DeepSeek有望在AI领域实现更广泛的应用和突破。
DeepSeek模型凭借其高效的训练方法、低成本的部署策略以及卓越的性能,在国内外AI领域引起了广泛关注,并为推动国产AI技术的发展提供了重要参考。
